
Introduction Link to heading
Kubernetes has become an essential tool in the Software Engineering industry. Everyone wants to use it, and most times, we successfully make it work, but it suddenly becomes the occult when it does not work the way we think it should. Let us take a moment to understand how it works and how to use it to deploy applications seamlessly.
So, what is Kubernetes? As official documentation mentions, it allows you to do “Production-Grade Container Orchestration”, but does this mean? Well, let’s take a step back. At this point, I hope you understand what a container is (if not, refer to my other post explaining containers), but in short, a container to run a process in isolation, allowing you as an application developer to create an image for your application and have some confidence that it is going to run the same way on every environment as it runs on your machine. Many tools allow you to create an image for your application and spin a container from it, such as Podman, containerd, cri-o, Docker, etc. (Anyone who has been working in the software development industry within the last five years should’ve atleast heard of Docker).
Now that you have a container for your application, you can use this image to deploy to production, but we still need to figure out
- Where is this container going to run?
- How is the underlying infrastructure set up?
- How is the network stack set up?
- If there is a surge or drop in my application’s traffic, how can we efficiently scale up or down?
- How do you manage configurations and secrets used by your application?
Creating containers is easy and reproducible, but there is still a lot to figure out on handling issues like the ones mentioned above. All of these issues fall into orchestration. Kubernetes can help you manage all of these problems in a scalable manner.
Understanding Kubernetes Link to heading
Let’s look at the different kinds of components available in Kubernetes.
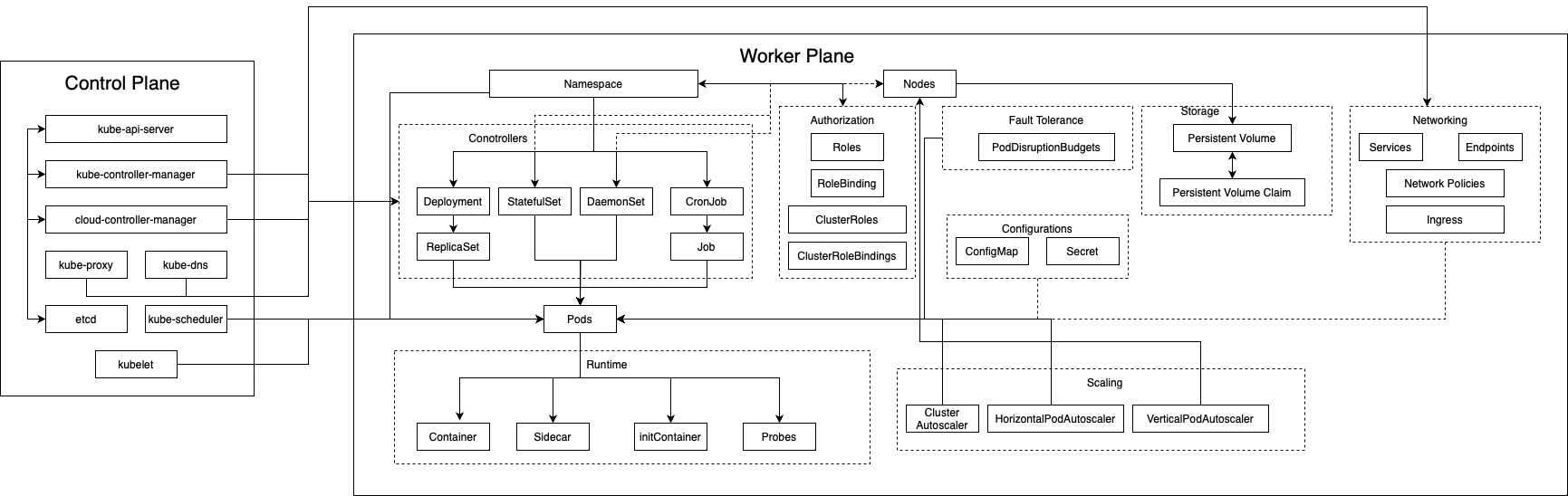
Elements in Kubernetes
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes 1. Pods can hold one or more containers, and they define the specifications of executing the containers. A Pod is similar to a set of containers with shared namespaces and shared filesystem volumes. Read more Linux containers in my other blog post.
Control Plane Link to heading
A Kubernetes control plane is a collection of services that manage all operations and elements on the worker plane in the Kubernetes cluster. It can be thought of as the brains of the Kubernetes cluster. To understand how Kubernetes works under the hood, it is vital to know how the control plane functions. Services like GKE (Google Kubernetes Engine), EKS (Elastic Kubernetes Service), and AKS (Azure Kubernetes Service) provide Kubernetes clusters where the cloud providers manage the control plane so the developers can focus on their application rather than addressing the Kubernetes infrastructure. The key elements of the control plane are as follows:
API Server Link to heading
The API server exposes the Kubernetes API, which is required to interact with the Kubernetes cluster. The main implementation of a Kubernetes API server is kube-apiserver. kube-apiserver is designed to scale horizontally—that is, it scales by deploying more instances. You can run several instances of kube-apiserver and balance traffic between those instances. 2
When using private clusters with cloud-provided services like GKE, AKS, and EKS, accessing the API cluster would require setting up VPC peering and opening the required firewall rules because the control plane will run the cloud provider’s VPC.
etcd Link to heading
etcd is a distributed and reliable key-value store. etcd in the control stores all the cluster data, including the cluster state. When using an on-prem Kubernetes cluster, always remember to setup a backup strategy for your Kubernetes etcd data store.
Scheduler Link to heading
The Kubernetes scheduler monitors newly created pods with no assigned nodes. It selects the node to run the pods on by considering resource requirements, controller type of the pod, node affinity/anti-affinity, data locality, hardware/software policy constraints, inter-workload interface, and deadlines.3
kube-scheduler is the implementation of the Scheduler.
kube-proxy Link to heading
Kubernetes pods are ephemeral, so IP addresses cannot be relied upon for sending requests to a container inside a pod. kube-proxy solves this problem by maintaining network rules on every Kubernetes node, which allows network communication to the pods from network sessions. kube-proxy uses the operating system packet filtering layer if there is one and it’s available. Otherwise, kube-proxy forwards the traffic itself 4.
As the size of the Kubernetes clusters increases, and the number of nodes increases, the size of IP tables managed by kube-proxy also increases exponentially because it needs to kube-proxy running on every node to control the routing rules of pods running on all the other nodes. Using network policies like Calico can help scale up a Kubernetes cluster.
kube-dns Link to heading
kube-DNS is a DNS server running on the Kubernetes cluster. It is responsible for resolving DNS names for pods and services. kube-dns also provides caching for DNS queries to improve performance. Kublet configures the pod’s DNS so containers can lookup Services by name rather than IP. See Kubernetes documentation for more details on Kubernetes DNS addons.
Controller Manager Link to heading
The controller manager is the component that runs all the controller processes. Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single operation. 5
There are many types of controllers. Some examples of them are:
Node controller: Responsible for noticing and responding when nodes go down.
Job controller: Watches for Job objects that represent one-off tasks, then creates Pods to run those tasks to completion.
EndpointSlice controller: Populates EndpointSlice objects (to provide a link between Services and Pods).
ServiceAccount controller: Create default ServiceAccounts for new namespaces.
The above is a partial list.
Cloud Controller Manager Link to heading
Cloud controller manager is an extension of the controller manager, which every cloud provider implements based on their infrastructure setup to provide services like GKE, EKS, and AKS.
Kubelet Link to heading
The kubelet is the primary “node agent” that runs on each node. It can register the node with the api-server using one of the hostname, a flag to override the hostname, or specific logic for a cloud provider. A kubelet is setup and managed by the Kubernetes administrator or the Cloud Provider of the managed Kubernetes service.6
Nodes Link to heading
Nodes are instances that physically (or virtually) support the execution of instances. All nodes are managed by the control plane to manage pod scheduling. Each node has a kubelet process running on it, which connects to the control plane and registers itself. Nodes can be managed individually or through a node pool. 7
Worker Plane Link to heading
Namespaces Link to heading
Namespaces in Kubernetes provide a mechanism for isolating groups of resources within the cluster. Names of resources have to be unique within the namespace but not across namespaces. These are similar to namespaces within Linux
Controllers Link to heading
Deployment Link to heading
A Kubernetes deployment defines the desired state of a stateless application. A deployment manages replicasets, which in turn control pods8. Deployments can allow you to:
- Rollout updates to your pods.
- Rollback changes to your pods.
- Scale up or down to facilitate more loads.
- Pause the rollout of your deployments.
- Clean up old replicasets that are not needed anymore.
Replicasets Link to heading
A ReplicaSet aims to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods. A ReplicaSet is defined with fields, including a selector that selects how to identify Pods it can acquire, several replicas indicating how many Pods it should maintain, and a pod template specifying the data of new Pods it should create to meet the number of replicas criteria. A ReplicaSet then fulfills its purpose by creating and deleting Pods as needed to reach the desired number. When a ReplicaSet needs to create new Pods, it uses its Pod template.
It is recommended to use deployments to manage pods through replicasets. 9
DaemonSets Link to heading
Daemonsets are used to make sure a set of pods gets scheduled on all the available nodes. Daemonsets are generally used for monitoring applications that are required to run on all nodes and collect logs and metrics. Some examples are Datadog agent and kube-proxy.
StatefulSets Link to heading
StatefulSet manages the deployment and scaling of a set of pods and guarantees the ordering and uniqueness of these pods.
Like a Deployment, a StatefulSet manages Pods based on an identical container spec. Unlike a Deployment, a StatefulSet maintains a sticky identity for each of its Pods. These pods are created from the same spec but are not interchangeable: each has a persistent identifier maintained across rescheduling.
If you want to use storage volumes to provide persistence for your workload, you can use a StatefulSet as part of the solution. Although individual Pods in a StatefulSet are susceptible to failure, the persistent Pod identifiers make it easier to match existing volumes to the new Pods that replace any that have failed.10
StatefulSets currently requires a Headless Service to be responsible for the network identity of the Pods. You are responsible for creating this Service.
CronJobs Link to heading
CronJobs are used to create jobs at regular intervals. CronJobs are helpful when creating jobs like scheduled backups, cleanups, report generation, etc. One CronJob object is like one line of a crontab (cron table) file on a Unix system. It runs a job periodically on a given schedule, written in Cron format. CronJobs have limitations and idiosyncrasies. For example, a single CronJob can create multiple concurrent Jobs in certain circumstances. Before using a CronJob, always be sure to check for CronJob limitations in the official Kubernetes documentation.
Jobs Link to heading
A Job creates one or more pods that retries execution until a specified number of them successfully terminate based on a cron schedule. As the pods are complete, the Job keeps track of the status of execution and termination of the respective pods.
Configurations Link to heading
ConfigMap Link to heading
ConfigMap is a way to decouple non-sensitive configurations from your application containers. A ConfigMap provides a way to mount the configurations of the configmap as a volume to the container. It should be remembered that a ConfigMap is supposed to hold a manageable amount of data. A ConfigMap is limited to using 1 MiB of data. Adding different volumes to the container is better if you need more data.11 It should also be remembered that changes to configmap do not automatically get reflected in the pod. To allow the pod to see the changes in the configmap, the controller needs to rollout restart so that the updated configmap can be mounted on the new pods.
Secrets Link to heading
Secrets are a way to store a small amount of sensitive data and decouple them from your application container. This way, an application can reference decoupled secrets from the container.
A Kubernetes holds data in base64 encoded format and are not encrypted and stored in plain text in the etcd in the Kubernetes control plane. Anyone with API access can access all the secrets. To make sure the secrets are secure, consider using the following:
- Encryption at rest in the cluster.
- Restrict API access and external etcd reads from the control plane.
- Consider using external secret providers like Vault. 12
Authorization Link to heading
Roles Link to heading
Roles are namespace-bound objects in Kubernetes that define rules for a set of Kubernetes APIs. These permissions are purely additive, i.e., no deny rules exist. With RoleBindings, a group of permissions can be defined for users to access resources within a namespace.
RoleBindings Link to heading
RoleBindings are namespace-bound objects used to assign a role to a subject, which can be users, groups, or service accounts.
ClusterRoles Link to heading
ClusterRoles are cluster-bound objects that, like Roles, define rules for a set of Kubernetes APIs. Although ClusterRoles are cluster-bound, cluster roles can bind permissions to specific namespaces with RoleBindings.
ClusterRoleBindings Link to heading
ClusterRoleBindings are cluster-bound objects that tie ClusterRoles to subjects (users, groups, or service accounts). These permissions are used to set the permissions of the subjects across the cluster, i.e., across all namespaces.
Storage Link to heading
Persistent Volumes and Persistent Volume Claims Link to heading
Read more about Persistent Volumes on my other post
Fault Tolerance Link to heading
PodDisruptionBudget Link to heading
A pod disruption event happens when, for some reason, pods disappear or are unable to get scheduled on nodes. This can be because of involuntary disruption (hardware failures, accidental deletion of VMs by cluster admins, a kernel panic, eviction of a pod because of the node running out of resources, etc.) or voluntary disruptions (draining a node for repair or upgrades, updating pod’s deployment pod template causing a restart, etc.).
PodDisruptionBudgets (PDBs) handle these disruptive events by specifying the minimum of pods to always be available during these events. A PDB limits the number of Pods of a replicated application that are down simultaneously from voluntary disruptions. For example, a quorum-based application would like to ensure that the number of replicas running is kept above the number needed for a quorum.
Autoscaling components Link to heading
Cluster Autoscaler Link to heading
Kubernetes cluster autoscaler is a Kubernetes component that adjusts the Kubernetes cluster size so that all the pods can be appropriately scheduled on the Kubernetes nodes.
Horizontal Pod Autoscaler Link to heading
Horizontal Pod Autoscaler (HPA) is used to scale up the number of pods based on CPU and memory metrics.
Vertical Pod Autoscaler Link to heading
Vertical Pod Autoscaler (VPA) is the component that scales the available CPU and memory of Kubernetes nodes based on the consumption of CPU and memory of the existing pods.
Networking Link to heading
Services Link to heading
Kubernetes services allow a way to expose your application running in one or more pods. Using a service allows a set of pods to accept any incoming traffic. As each pod gets its IP address, defining a route to a service running in multiple pods can be tricky since a controller-like deployment can restart and replace pods often, which is where a Service comes into the picture. Using a Service, developers do not need to worry about the changing IP address of the pods.
A service can provide mechanisms for traffic management and load balancing across the different application pods.
Headless services Link to heading
Sometimes, you don’t need load-balancing and a single Service IP. In this case, you can create headless Services by explicitly specifying “None” for the cluster IP address (.spec.clusterIP).13
Endpoints and EndpointSlices Link to heading
In the Kubernetes API, an Endpoints (the resource kind is plural) defines a list of network endpoints, typically referenced by a Service to define which Pods the traffic can be sent to. 14
Kubernetes’ EndpointSlice API provides a way to track network endpoints within a Kubernetes cluster. EndpointSlices offer a more scalable and extensible alternative to Endpoints.
NetworkPolicies Link to heading
NetworkPolicies provide a way for traffic management and routing at the L3 and L4 (Network and Transport layer of the OSI network model). NetworkPolicies are an application-centric construct allowing you to specify how a pod can communicate with various network “entities”.
Ingress Link to heading
Ingress defines how external traffic is accepted and routed in the cluster. Ingress may provide load balancing, SSL termination, and name-based virtual hosting. There are more sophisticated ingress solutions available which extend the feature of the Kubernetes ingress like Istio, Ambassador and Traefik.
References Link to heading
https://kubernetes.io/docs/concepts/overview/components/#kube-apiserver ↩︎
https://kubernetes.io/docs/concepts/overview/components/#kube-scheduler ↩︎
https://kubernetes.io/docs/concepts/overview/components/#kube-proxy ↩︎
https://kubernetes.io/docs/concepts/overview/components/#kube-controller-manager ↩︎
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/ ↩︎
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/ ↩︎
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/ ↩︎
https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/ ↩︎
https://kubernetes.io/docs/concepts/configuration/configmap/ ↩︎
https://kubernetes.io/docs/concepts/configuration/secret/ ↩︎
https://kubernetes.io/docs/concepts/services-networking/service/#headless-services ↩︎
https://kubernetes.io/docs/concepts/services-networking/service/#endpointslices ↩︎